Automating a Twitter Bot with AWS Lambda
A little how-to guide on how I setup a twitter bot to tweet random screenshots from King of the Hill
Update: Twitter is a bit of a mess these days, in case you haven't heard, so your mileage may vary in terms of your ability to use the Twitter API. However, I've written a new version of this post specifically for Mastodon!
I’ve always been a fan of The Simpsons and have been following @simpscreens on Twitter for a while, an account that tweets a random frame of the show every 30 minutes. It's pretty entertaining catching the occasional out-of-context image from the show in my Twitter feed so I decided to set out and create my own version for another of my favorite animated sitcoms: King of the Hill. You can check it out here: @kothscreens

The approach
When deciding how to go about creating this, I could have easily scripted a cron job to run on an EC2 instance every 30 minutes but it seemed very inefficient. I would have to maintain an entire server and keep it updated and running 99.9% of the time just for a little Python script. No thank you. The AWS service Lambda seemed like a much better fit. In case you aren’t aware, Lambda is a service that provides serverless architecture to run Python and Node.js scripts based off of specific triggers. It’s super cool, and basically free! Their free tier (which does NOT expire after 12 months) allows for up to 1 Million requests per month / 400 GB-seconds of compute time per month. Because of that, I’m just paying for the photo storage on S3 which is around 10 cents/month.
Snap some pics
First things first, I needed to gather my images. Using the ffmpeg CLI, I was able to run through all of the video files, take a screenshot every 1 second, and output to a folder. Hand-drawn animation is typically 12 fps, but I figured 1 fps should suffice for this project. For a single video file, that command looks something like this:
ffmpeg.exe -i "F:\King of the Hill\King of the Hill\Season 01\104 - Hank's Got the Willies.mkv" -qscale:v 10 -r 1 -f image2 F:\frames\frame%03d.jpg -hwaccel dxva2
Uploading to S3 - the easy way!
Once I collected all of the screenshots, it was time to upload to S3. I opened up the S3 service in my browser, navigated to the folder containing the screenshots for episode 1, and… oh, man this is going to take forever. I was uploading a TON of small files from a network with slow upload speeds to begin with. I needed a better way to do this. So, instead of uploading through the web application, I decided to zip up the folders by TV season and upload to an EC2 instance just temporarily over FTP. With the help of the AWS CLI, I scripted a solution that would unzip the seasons/episodes and move the images from the EC2 server to S3. Much faster! Moving all files from your working folder to S3 is as easy as:
aws s3 cp ./ s3://your-bucket/ --recursive
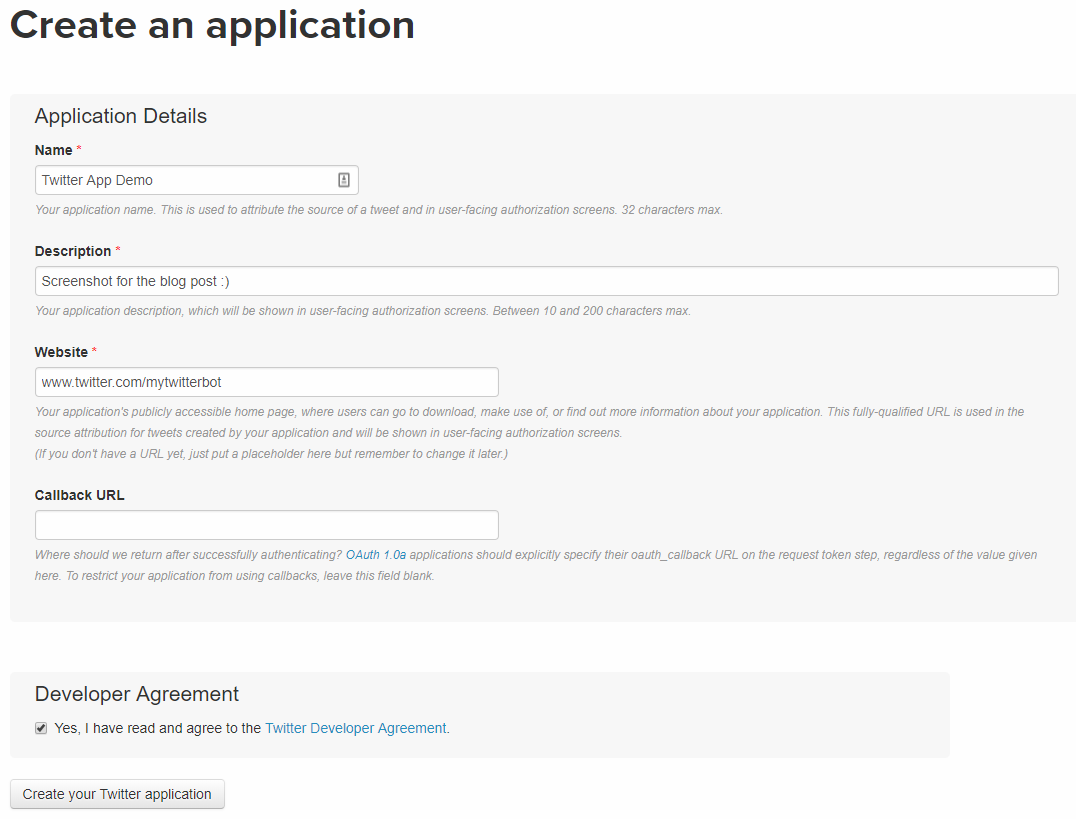
Create your Twitter app
Next head over to https://apps.twitter.com/ and create an application to get your API keys. Don’t worry about the website requirement, just throw in your Twitter account URL or whatever. Make sure to copy down your consumer key and consumer secret. You'll also need your access token and access token secret.
Write your python script
First off, create a script called secrets.py and throw your Twitter API keys and tokens in here:
consumer_key = 'enter_your_consumer_key_here'
consumer_secret = 'consumer_secret_goes_here'
access_token = 'replace_with_access_token'
access_secret = 'you_know_what_goes_here'
Updated 2/11/21
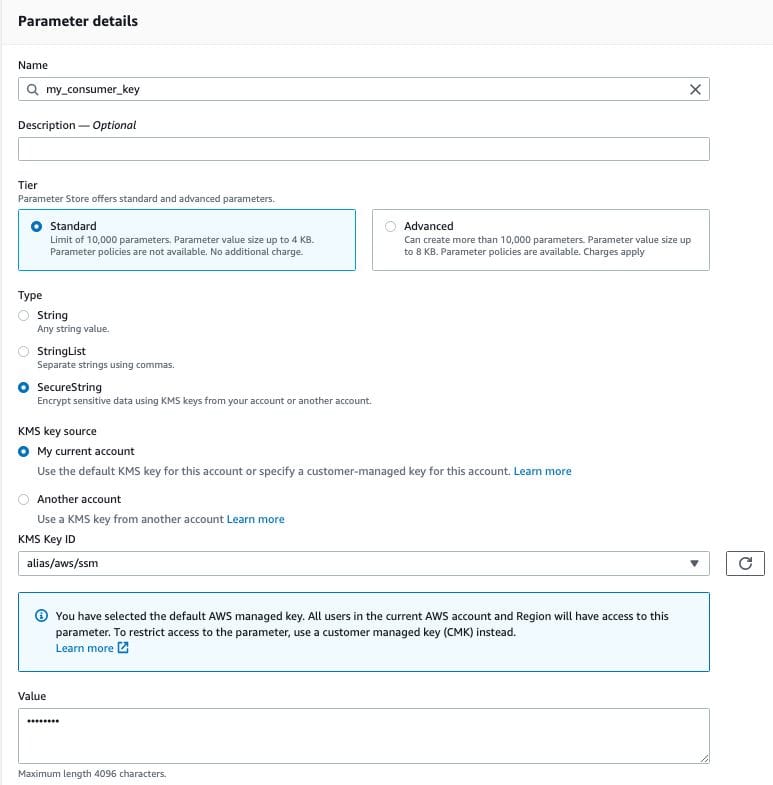
I've since moved away from keeping these secrets and tokens in plaintext within the lambda function and instead moved them all to parameter store within AWS Systems Manager. It's pretty easy to setup and I've opted to store everything as a SecureString which encrypts the parameters. By storing them as standard parameters, there is also no charge. I've updated the code below to reflect my changes here and how I retrieve the parameters.
Now, we're going to use python modules tweepy and boto3 (among others) in our main script. Tweepy is a python wrapper for the Twitter API and boto3 will let you use the AWS SDK in python. Here's how I setup my script send_tweet.py:
import requests
import tweepy
import boto3
import botocore
import os
import random
#This next import was for the old way of doing things
#from secrets import *
# Event, context parameters required for AWS Lambda
def send_tweet(event, context):
ssm = boto3.client('ssm')
auth_keys = ssm.get_parameters(
Names=['koth_screens_access_secret',
'koth_screens_access_token',
'koth_screens_consumer_key',
'koth_screens_consumer_secret'
],
WithDecryption=True
)
access_secret = auth_keys['Parameters'][0]["Value"]
access_token = auth_keys['Parameters'][1]["Value"]
consumer_key = auth_keys['Parameters'][2]["Value"]
consumer_secret = auth_keys['Parameters'][3]["Value"]
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
# Twitter requires all requests to use OAuth for authentication
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
s3 = boto3.resource('s3')
BUCKET_NAME = 'myBucket'
# empty array for key values
keyArray = []
s3bucket = s3.Bucket(BUCKET_NAME)
# 13 seasons of King of the Hill
randomSeason = random.randint(1,13)
# different number of episodes for every season
episodeDict = {1:12,
2:23,
3:25,
4:24,
5:20,
6:21,
7:23,
8:22,
9:15,
10:15,
11:12,
12:22,
13:24}
randomEpisode = random.randint(1,episodeDict[randomSeason])
# convert int values to string for looking up key in S3
randomSeason = str(randomSeason)
randomEpisode = str(randomEpisode)
# filter out all objects based on season # and episode #
for obj in s3bucket.objects.filter(Prefix=randomSeason+"/"+randomEpisode+"/"):
#add all frame key values from episode to an array
keyArray.append('{0}'.format(obj.key))
# get number of frames for an episode based on length of array
numFrames = (len(keyArray))
# get a random frame number
randomFrame = random.randint(0,numFrames)
# grab frame key from array
KEY = (keyArray[randomFrame])
# download frame jpg from s3 and save to /tmp
pic = s3.Bucket(BUCKET_NAME).download_file(KEY, '/tmp/local.jpg')
user=api
# tweet picture
user.update_with_media('/tmp/local.jpg')
# delete local image
os.remove('/tmp/local.jpg')
#image is tweeted, nothing to return
return None
In other words:
I organized my bucket where each season is just the number of the season and each episode is the number of the episode in that season. Since there were 13 seasons of King of the Hill, set randomSeason to be a random integer between 1 & 13. Since there is a different number of episodes per season, I created a dictionary to determine the value of randomEpisode based on the value of the season number.
Once I've got these values, I converted them to strings. This is because S3 isn't going to play nice if we hand it over integers for the filter. Once we can filter on the season and episode number, we can find out how many frames there are for this specific episode just by getting the length of the array. Pick a random number between 0 and the total number of frames and now we have our random frame.
With Lambda, you are allowed to save files locally to the /tmp directory, so I just download the image to this location, tweet out the image, and delete.
Ready for Lambda
Amazon already has a pretty good guide on creating a Python deployment package right here, but I'll fill in some of the gaps and specifics for this Twitter bot. Make sure your scripts and modules are all locally saved to the same folder. Now select all of your content and zip it up (don't zip the parent folder!!!!). Once you've uploaded your zip file, you need to setup a trigger to kick off your script. In my case, I just wanted it to run every 30 minutes. Triggers based around time & date can be made with Cloudwatch events:

Now you can sit back and let your script do its own thing every 30 minutes!
It's possible I forgot something crucial since I wasn't documenting this every step of the way. If that's the case, feel free to comment below and I'll see what I can do to help!
